Project Proposal
Summary: We are going to simulate the movement of stars with acquired data and the Barnes-Hut algorithm on the NVYDIA GPUs.
Background:
There are billions of stars in our universe, and we would like to simulate their movement based on the forces these stars encounter with each timestep. In order to do this, we would like to use the computing power of the NVYDIA GPUs to help us efficiently simulate this many stars using the Barnes-Hut algorithm. We hope to run this simulation with data from the European Space Agency.
To do this, we will be using Burtscher's and Pingali's paper An Efficient CUDA Implementation of the Tree-Based Barnes Hut n-Body Algorithm, which provides us with a solid foundation on an efficient design and many different optimizations we could try. From this paper, we know that there are essentially six steps of computation in this algorithm, which we could split up into six kernels so that we could more easily control the thread and block sizes we are using:
Background:
There are billions of stars in our universe, and we would like to simulate their movement based on the forces these stars encounter with each timestep. In order to do this, we would like to use the computing power of the NVYDIA GPUs to help us efficiently simulate this many stars using the Barnes-Hut algorithm. We hope to run this simulation with data from the European Space Agency.
To do this, we will be using Burtscher's and Pingali's paper An Efficient CUDA Implementation of the Tree-Based Barnes Hut n-Body Algorithm, which provides us with a solid foundation on an efficient design and many different optimizations we could try. From this paper, we know that there are essentially six steps of computation in this algorithm, which we could split up into six kernels so that we could more easily control the thread and block sizes we are using:
- Compute bounding box around all bodies, which is the root node of the octree, a three dimensional version of a binary tree, that we will be building.To compute this bounding box, we have to efficiently find the minimum and maximum coordinates in our three planes.
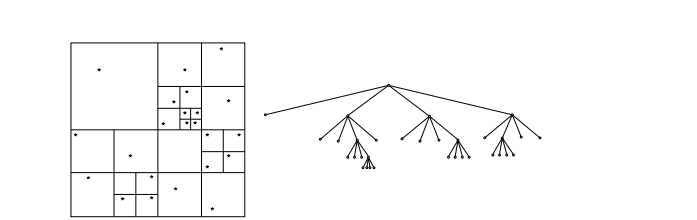
- Build hierarchical decomposition by inserting each body into octree. This is done by dividing cells over and over until each cell has at most one body. The body is then added into our array-represented octree using locks. Below is a picture from Burtscher and Pingali's paper that is a visualization of this division and the octree that represents it.
- Summarize body information in each internal octree node. This step computes the center of gravity and summed mass of the bodies by traversing the tree starting from the bottom and going up
- Approximately sort the bodies by spatial distance. This step isn't needed for correctness, and would just make performance better for locality. It would sort the bodies by starting from the start of the tree.
- Compute forces acting on each body with the help of octree. This step calculates the force on each body starting at the root of the tree. We travel to a cell, and check whether a certain center of gravity is far enough away so that we could just calculate the effects the center of gravity and mass has on a body rather than calculating the effects all of the bodies in the subcells have on a specific body.
- Update body positions and velocities.
Each of these steps can take an extraordinary amount of time without parallelization. Luckily, there are a vast amount of optimizations that can be implemented for them such as but not limited to the following:
As we progress through the project, we hope to have our algorithm run as fast as possible through keeping these potential optimizations in mind. We also would like to have some sort of visualization for this algorithm, so that our updates are visible.
.
The Challenge:
In the Barnes-Hut Algorithm, an equal number of bodies per processor does not mean that there's an equal amount of work per processor, so splitting up the work is problematic. Additionally, we want to preserve locality, meaning we want to calculate star movement simultaneously for stars that are close to one another. But doing this while trying to get an equal amount of work per processor is difficult.
With regards to implementing the Barnes-Hut algorithm on the GPUS, Burtscher and Pingali expressed their concerns as the following:
1) It repeatedly builds and traverses an irregular tree-based data structure. (This tree structure also adds a lot of data dependencies that we have to work around. )
2) It performs a lot of pointer-chasing memory operations
3) It is typically expressed recursively., which isn't supported by current GPUs.
Resources:
Platform Choice: We are implementing Barnes-Hut using the CUDA on the GHC cluster NVDIA GPUs. We chose this platform because the algorithm that is described in the “Background” section above performs the same computation on multiple data, which means a SIMD architecture may be used. CUDA allows data to be run on parallel SIMD architectures.
Schedule:
Week 1: Complete by 11/5
Week 2: Complete by 11/12
Implement the first three kernels
Week 3: Complete by 11/19
Implement the remaining required kernels
Write checkpoint report
Week 4: Complete by 11/26
Implement a visualization of the simulation
Implement this kernel for speedup
Approximately sort the bodies by spatial distance
Week 5: Complete by 12/3
Find a time step that works well across data sets
Parse real star data in CSV files so it can be used in the project
Week 6: Complete by 12/10
Go back through code to implement optimizations as described in the background section
Week 7: Complete by 12/15
Collect any necessary data about performance
Write final report
- Minimizing memory accesses
- Maximizing data coalescing
- Reusing Data
- Minimizing data transfer from the CPU to the GPU
- Minimizing thread divergence (through minimizing conditionals/computing similar data in the same threads)
- Combining operations
- Using pragmas to parallelize loops
- Minimize locking
- Using hardware capabilities through using built-in operations (i.e. __syncthreads)
- Maximizing thread count
As we progress through the project, we hope to have our algorithm run as fast as possible through keeping these potential optimizations in mind. We also would like to have some sort of visualization for this algorithm, so that our updates are visible.
.
The Challenge:
In the Barnes-Hut Algorithm, an equal number of bodies per processor does not mean that there's an equal amount of work per processor, so splitting up the work is problematic. Additionally, we want to preserve locality, meaning we want to calculate star movement simultaneously for stars that are close to one another. But doing this while trying to get an equal amount of work per processor is difficult.
With regards to implementing the Barnes-Hut algorithm on the GPUS, Burtscher and Pingali expressed their concerns as the following:
1) It repeatedly builds and traverses an irregular tree-based data structure. (This tree structure also adds a lot of data dependencies that we have to work around. )
2) It performs a lot of pointer-chasing memory operations
3) It is typically expressed recursively., which isn't supported by current GPUs.
Resources:
- NVYDIA GPUs
- Cuda Documentation
- Lecture Notes on Barnes-Hut
- An Efficient CUDA Implementation of the Tree-Based Barnes Hut n-Body Algorithm by Martin Burtscher, Keshav Pingali (http://iss.ices.utexas.ediss.ices.utexas.edu/Publications/Papers/burtscher11.pdfu/Publications/Papers/burtscher11.pdf)
- Plan to Achieve:
- Implement Barnes-Hut with CUDA according to paper. The algorithm and its implementation in the paper are described in the “Background” section above.
- Build a visualization of the changes in location of the stars.
- Find a time step that works well across multiple data sets.
- Implement the following optimizations:
- Approximately sort the bodies by spatial distance using a kernel. This is discussed in the paper.
- Keep other optimizations in mind while coding (e.g. try to minimize memory accesses in implementation).
- Hope to Achieve: Poster Session Demo:
- Try different partitioning approaches.
- Generate a better picture (prettier and improve update speed/transitions).
- Implement O(n^2) algorithm for comparison.
- Attempt to optimize further.
- Deliverables:
- Speedup graphs for different versions of our code.
- Visualization of the simulation that shows the stars moving.
- Capability/Performance: We can show speedup graphs for different versions of our code to demonstrate the effect on performance our optimizations had. Also, if we end up implementing the O(n^2) algorithm for comparison, we can show the speedup we get from running Barnes-Hut.
Platform Choice: We are implementing Barnes-Hut using the CUDA on the GHC cluster NVDIA GPUs. We chose this platform because the algorithm that is described in the “Background” section above performs the same computation on multiple data, which means a SIMD architecture may be used. CUDA allows data to be run on parallel SIMD architectures.
Schedule:
Week 1: Complete by 11/5
- Implement code to generate random star data (Elora)
- Start implementing framework (Gabi)
Week 2: Complete by 11/12
Implement the first three kernels
- Compute bounding box around all bodies
- Build hierarchical decomposition by inserting each body into octree
- Summarize body information in each internal octree node
Week 3: Complete by 11/19
Implement the remaining required kernels
- Compute forces acting on each body with the help of octree
- Update body positions and velocities
Write checkpoint report
Week 4: Complete by 11/26
Implement a visualization of the simulation
Implement this kernel for speedup
Approximately sort the bodies by spatial distance
Week 5: Complete by 12/3
Find a time step that works well across data sets
Parse real star data in CSV files so it can be used in the project
Week 6: Complete by 12/10
Go back through code to implement optimizations as described in the background section
Week 7: Complete by 12/15
Collect any necessary data about performance
Write final report
